
A Beginner's Guide to Understanding Generative AI
Key AI concepts like "training", "inference", "hallucination", "fine-tuning" and "RAG" are put into simple terms for publishing professionals.
Designers: Jonathan Woahn, Michael Moulton / Tools: MidJourney, Recraft, Photoshop
A Quick Introduction
This article is a companion piece to a four-part series on AI and the Future of Book Publishing. It's written specifically for people in the book industry who want to understand the foundational concepts of generative AI without needing a technical background.
We're going to focus on generative text AI—the technology behind tools like ChatGPT that can read, understand, and generate human-like text. No prior AI knowledge is assumed. By the end of this article, you'll understand the key concepts that matter most for publishers: training, inference, hallucinations, fine-tuning, and RAG.
Let's First Align on Some Basic Vocabulary
As Stephen Covey wrote in The 7 Habits of Highly Effective People: "Seek first to understand, then to be understood." Before we dive in, let's make sure we're speaking the same language.
Here are the key terms you'll need:
- AI (Artificial Intelligence): A general term for computer systems that can understand, generate, and interact via text, audio, video, and other media. It's a broad category that encompasses many different technologies.
- Foundational Model: A set of mathematical instructions programmed into a computer to accomplish specific tasks. Think of it as the "brain" of an AI system—the underlying architecture that makes everything work.
- LLM (Large Language Model): A specific type of foundational model that focuses on understanding and generating text. ChatGPT is powered by an LLM. These models are "large" because they've been trained on enormous amounts of text data.
- ChatGPT: A popular AI chatbot application built by OpenAI. It's the "app" that most people interact with, but it's powered by an LLM under the hood.
- OpenAI: The company that built ChatGPT and the GPT series of language models. Other companies building similar technology include Anthropic (Claude), Google (Gemini), and Meta (LLaMA).
Artificial Intelligence Today Is Not Actual "Intelligence"
This is perhaps the most important misconception to clear up. Despite the name, ChatGPT doesn't think. It doesn't understand in the way humans do. It doesn't have beliefs, opinions, or consciousness.
What ChatGPT does is predict. Given a sequence of text (your prompt), it predicts the most likely next sequence of text (its response). It does this using incredibly complex statistical methods—analyzing patterns learned from billions of pages of text.
But here's the thing: people are good at this too. We predict all the time. We finish each other's sentences. We know what someone's going to say before they say it. We fill in blanks automatically.
Predicting Common Phrases
Let's try an exercise. Can you complete these familiar phrases?
- Break a ___
- Piece of ___
- My lips are ___
- Two heads are better than ___
- That's a load off my ___
If you said "leg," "cake," "sealed," "one," and "mind"—congratulations, you just performed inference. You predicted the most likely next word based on patterns you've internalized over years of reading, listening, and speaking.
An LLM does exactly the same thing—just at a much larger scale, across many more patterns, and with the ability to generate entirely new sentences, paragraphs, and documents based on those patterns.
How Is an LLM Able to Create Its Predictions?
The honest answer involves extraordinarily complex mathematics—linear algebra, calculus, probability theory, and neural network architectures that would take years of study to fully understand.
If you're curious about the technical details, there's an excellent interactive visualization called Transformer Explainer from Georgia Tech that lets you see how a language model processes text in real-time.
But for our purposes, we don't need the math. We need an analogy.
The Magic Box Analogy
Imagine I show you a magic box. You put a number in, and a different number comes out. Your job is to figure out the rule.
Magic Box #1
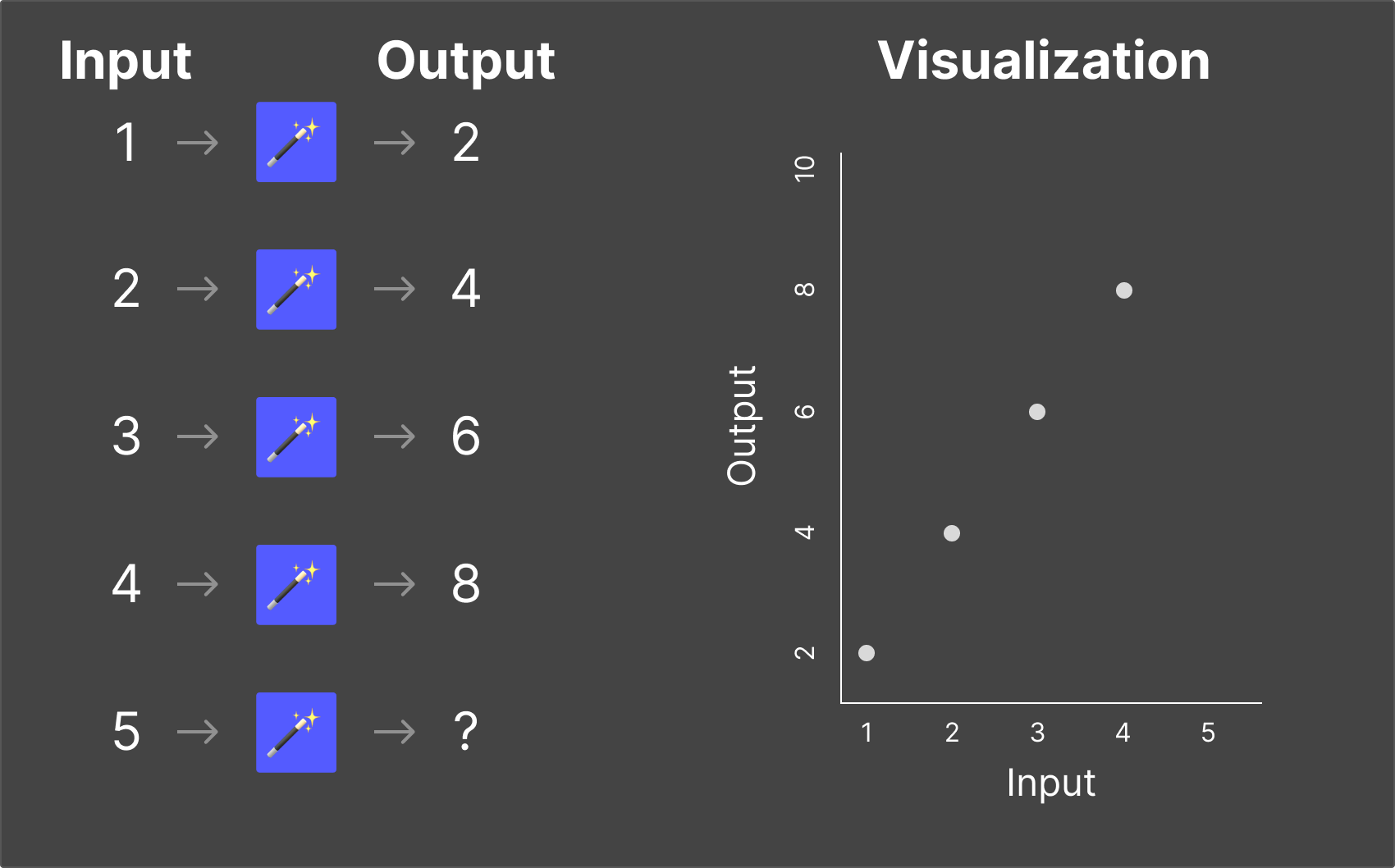
You put in 2, and 4 comes out. You put in 3, and 6 comes out. You put in 5, and 10 comes out.
The rule? Multiply by 2. Simple enough. Now if I put in 7, you can confidently predict the output: 14.
Magic Box #2
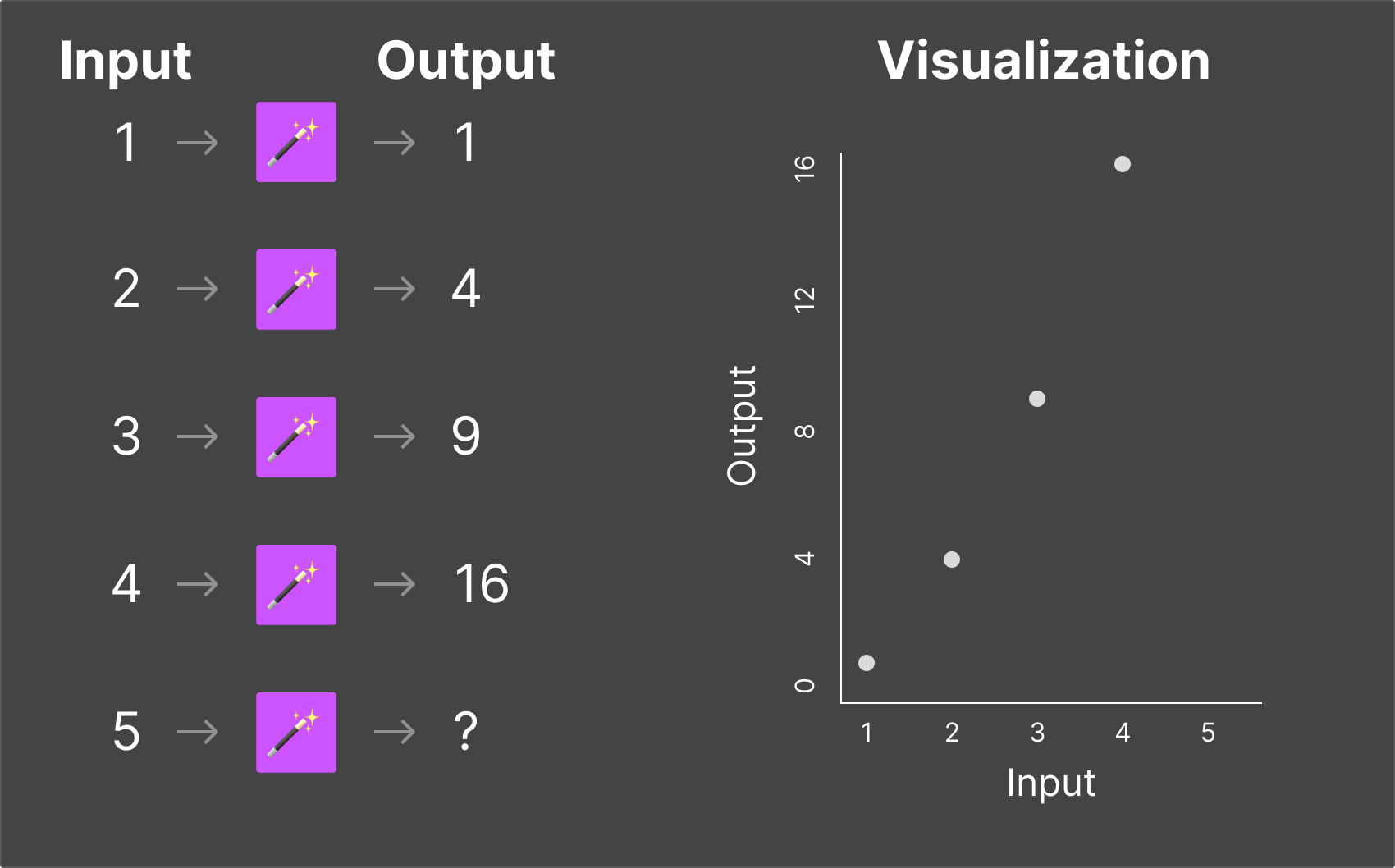
This one's a bit more complex. You put in 2, and 7 comes out. You put in 3, and 12 comes out. You put in 5, and 22 comes out.
After some thought, you figure out: multiply by 5, then subtract 3. Now if I put in 10, you can predict: 47.
Magic Box #3
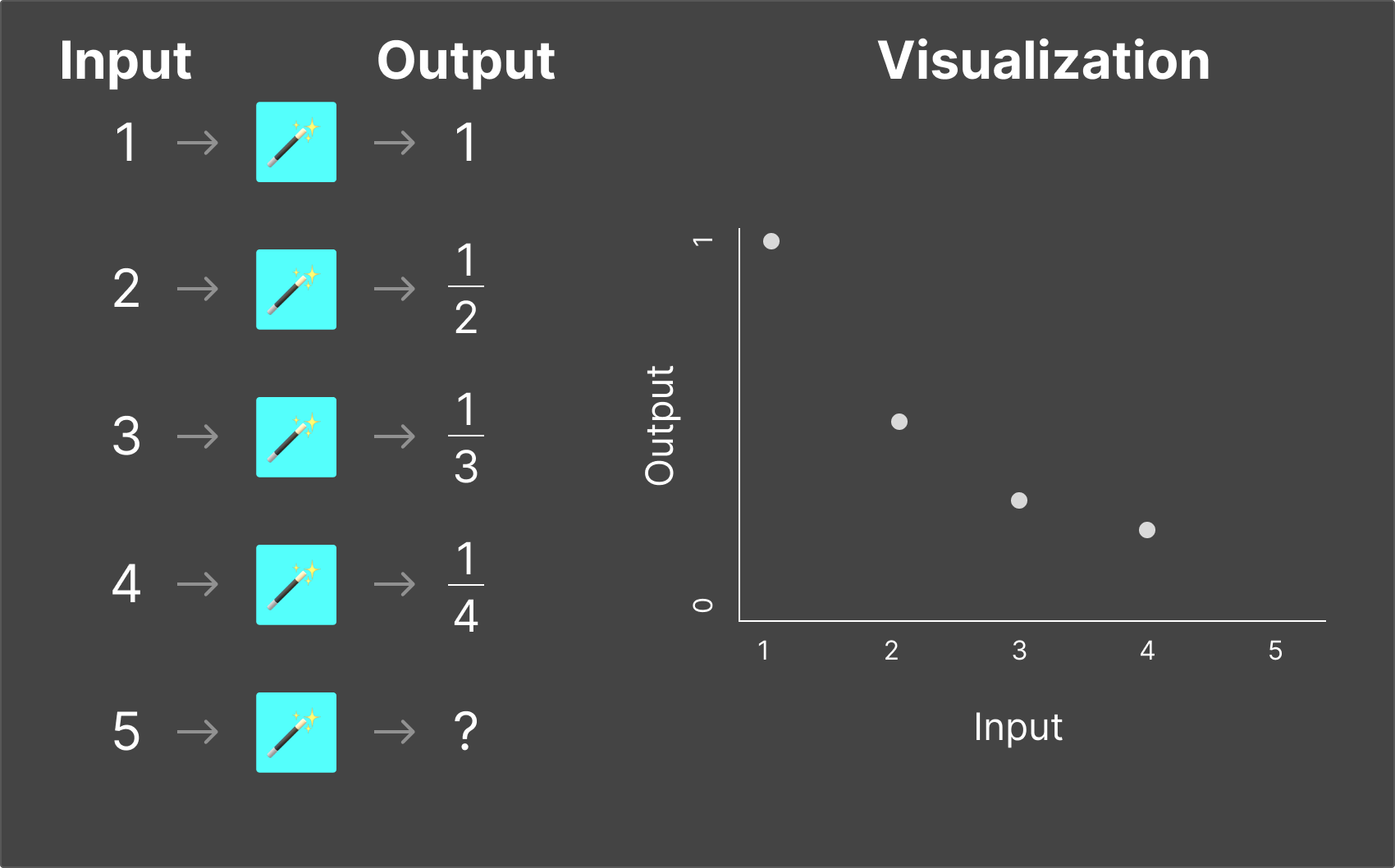
Now imagine the magic box takes in two numbers and produces one output. The rule is harder to spot, but with enough examples, you'd eventually figure it out.
Magic Box #4
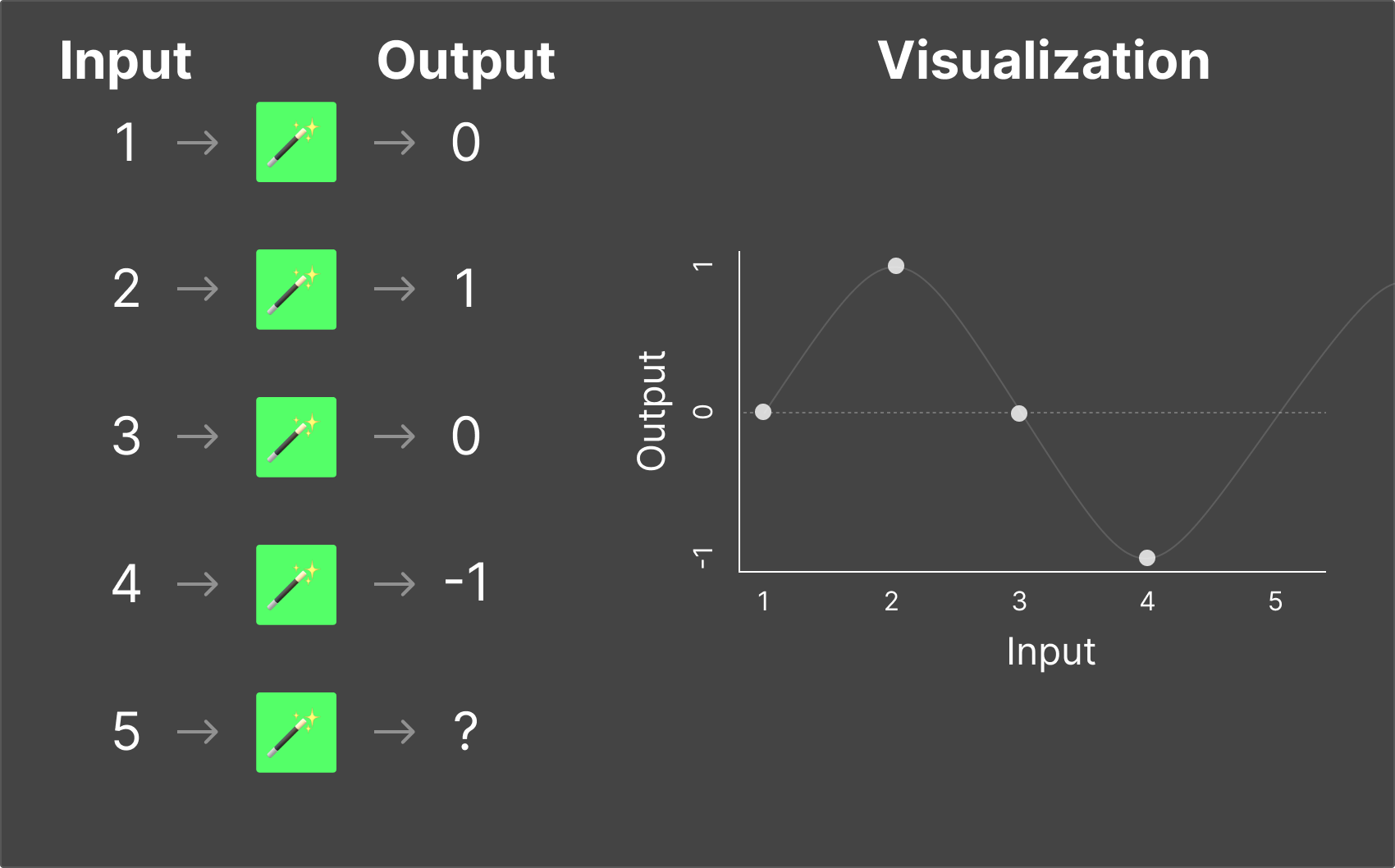
Now imagine the box takes in three numbers and outputs two numbers. The relationships become much harder for a human to identify—but not impossible with enough data and patience.
An LLM is essentially a magic box with billions of inputs and billions of outputs. The "rule" it's learning isn't simple arithmetic—it's the patterns, structures, and relationships in human language. And instead of you figuring out the rule by hand, the computer uses mathematical optimization to find it automatically.
Training
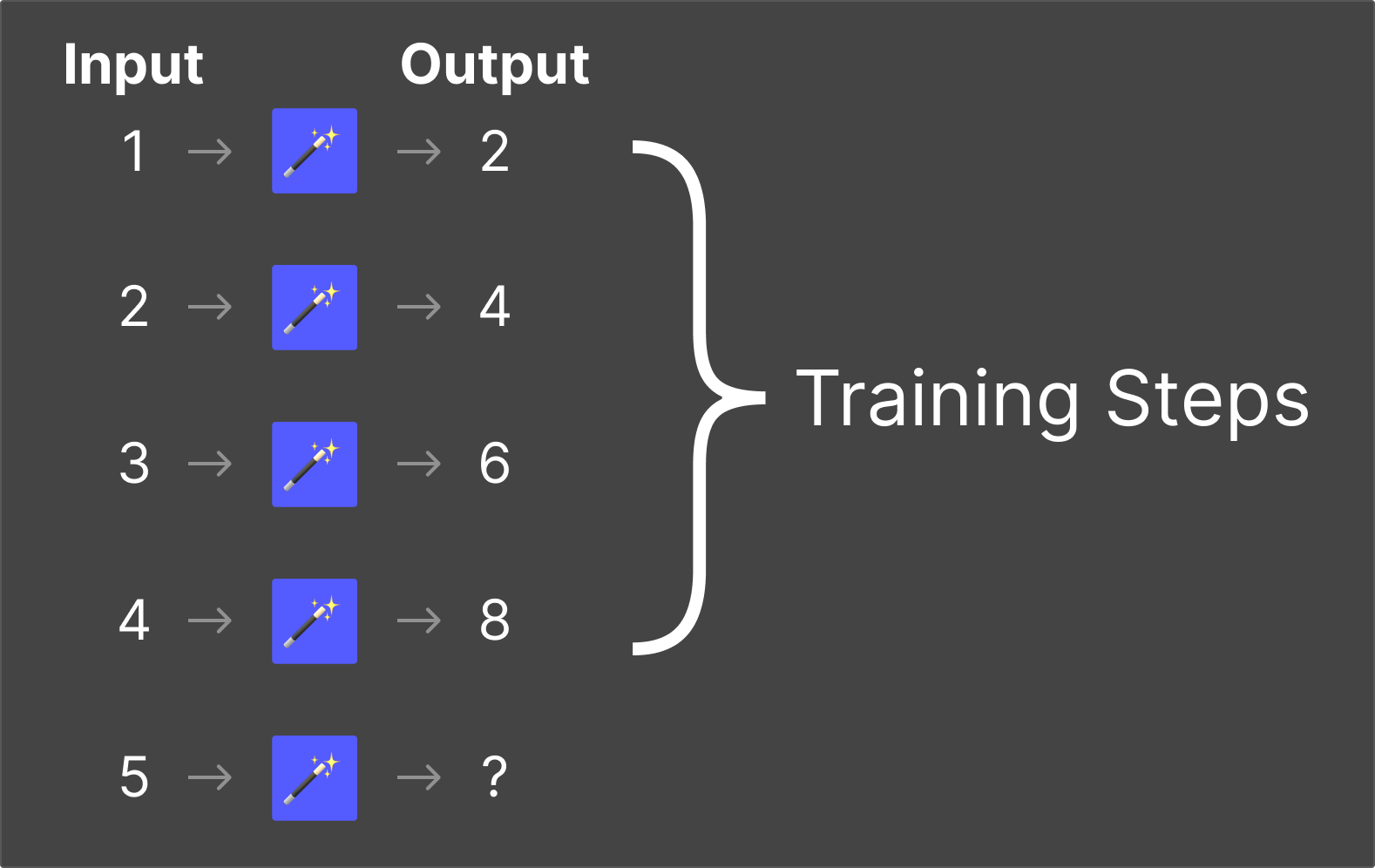
Training is the process where an LLM learns the rules of the magic box. During training, developers provide the model with both inputs and expected outputs—billions of text examples from books, websites, articles, and other sources.
The model analyzes these examples and gradually adjusts its internal parameters (think of them as billions of tiny dials) until it can accurately predict outputs from inputs. This process takes weeks or months and costs tens or hundreds of millions of dollars in computing resources.
The critical point: training is where the AI system learns. It's consuming and internalizing content at this stage—building the internal "rules" it will use later.
Inference
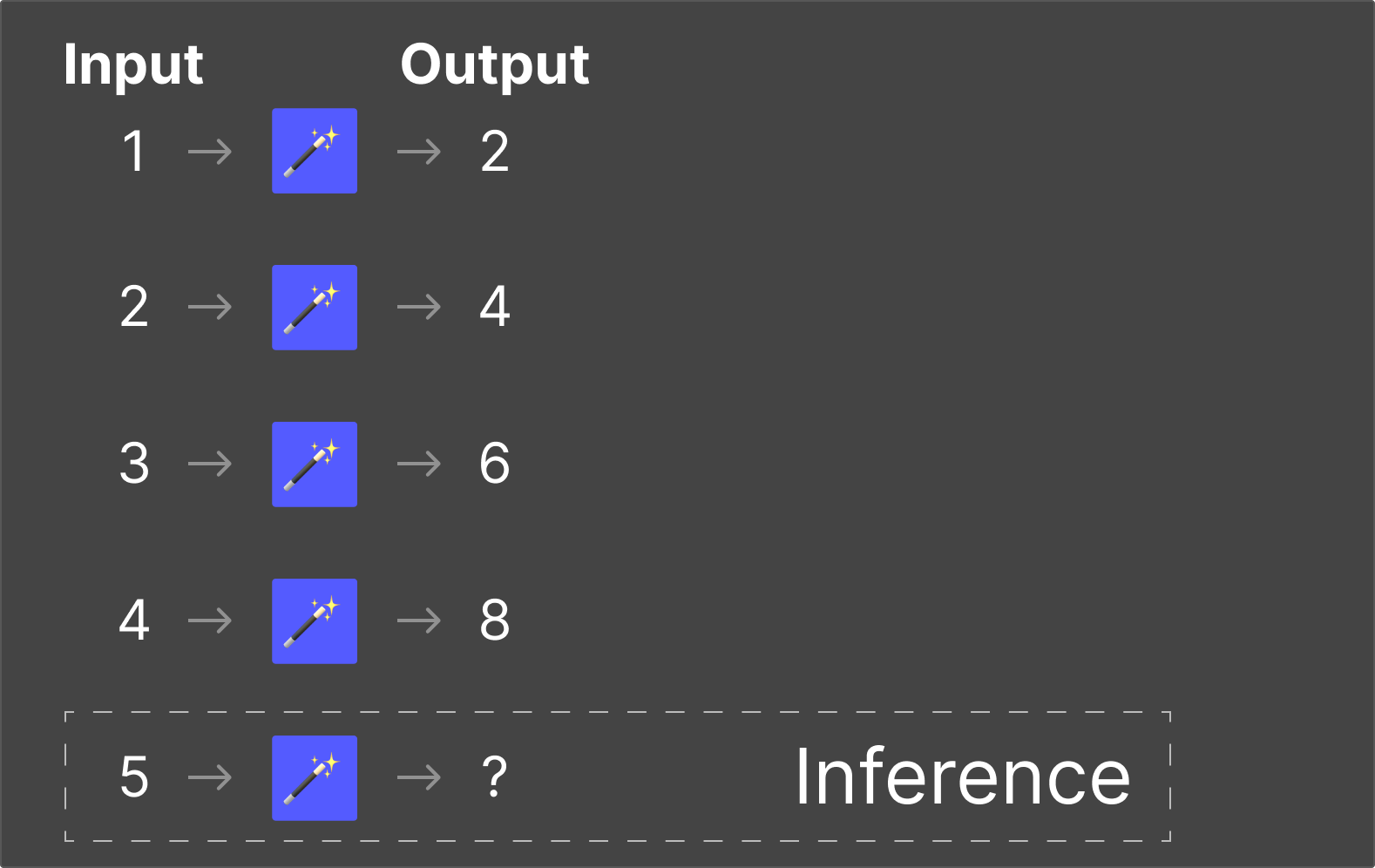
Inference is where the LLM applies what it learned during training. When you type a question into ChatGPT and it responds, that's inference. The model is using the patterns it internalized during training to predict the most appropriate response to your input.
Think of it this way: training is like going to school. Inference is like doing your job. You spend years learning (training), and then you apply that knowledge in real-world situations (inference).
Once an LLM understands the rules of language—grammar, context, meaning, style, tone—it can confidently generate responses to scenarios it has never explicitly encountered before. That's the power of inference.
Hallucinations
Sometimes, an LLM encounters a question outside the scope of what it learned during training. But here's the thing: it will still try to answer.
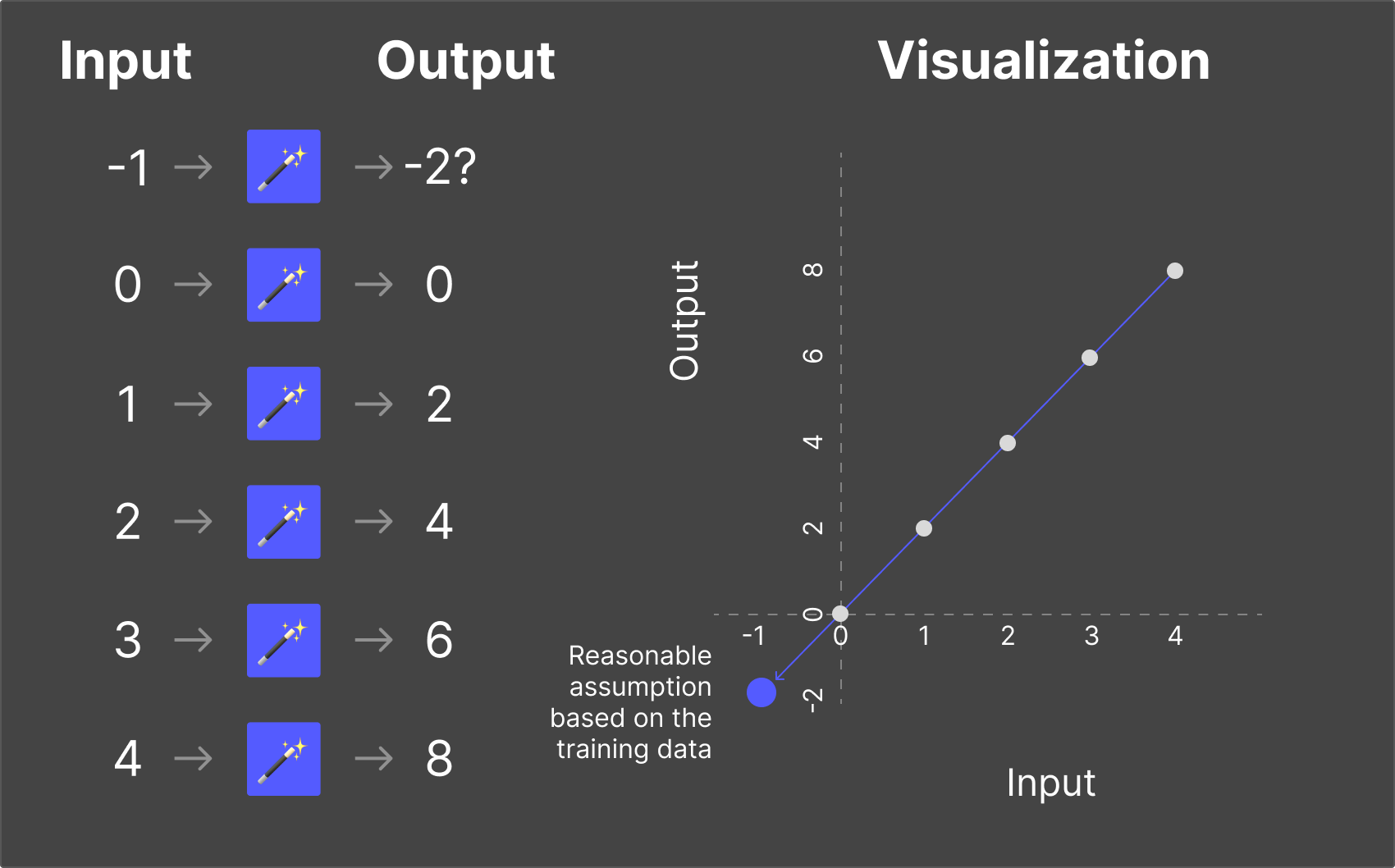
The model doesn't know what it doesn't know. It has no mechanism for saying "I have no idea." Instead, it generates the most statistically likely response—even if that response is completely wrong.
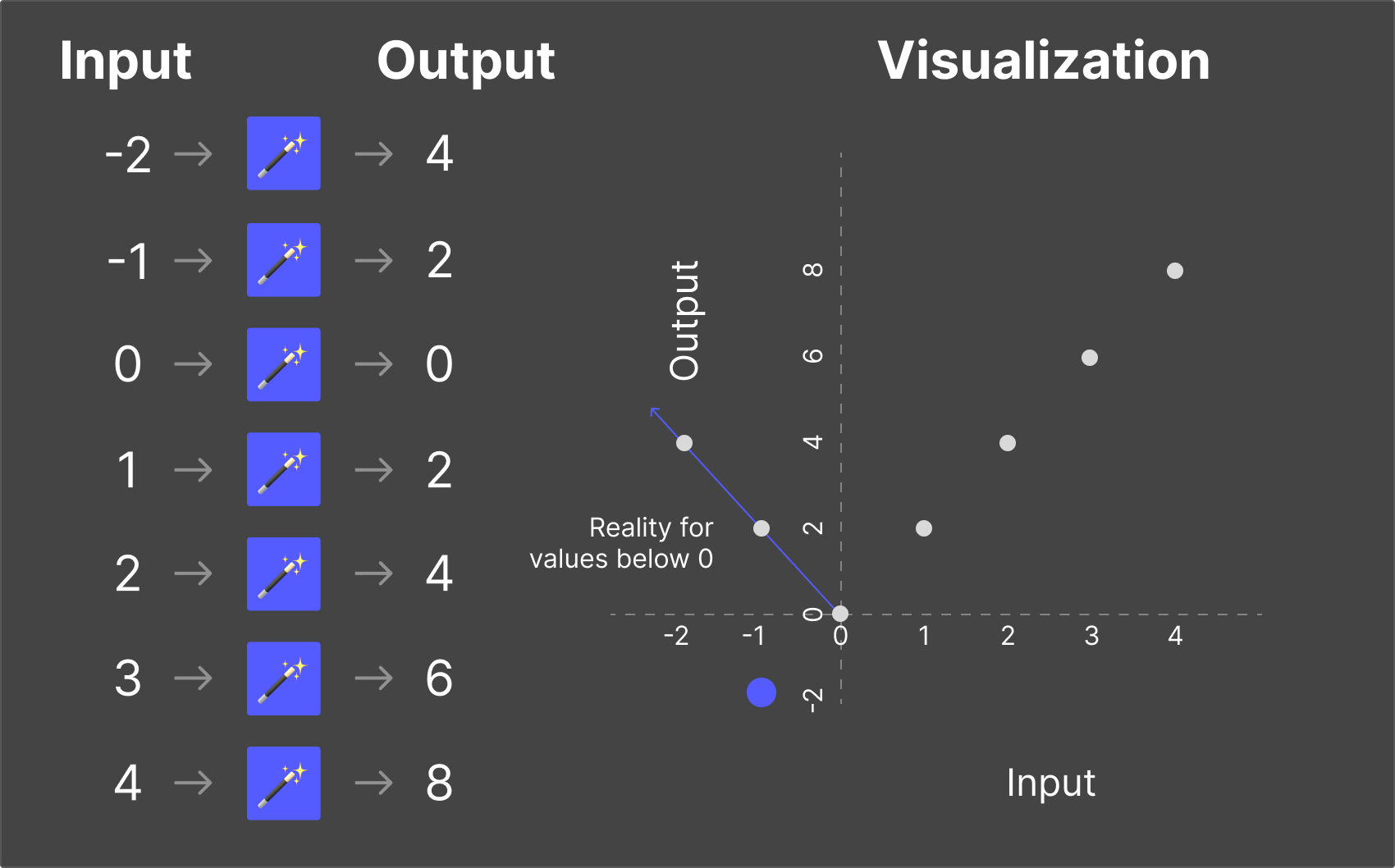
This is called a hallucination—when an LLM generates a confident, plausible-sounding response that is factually incorrect. The model isn't lying (it has no concept of truth or deception). It's simply making its best prediction based on patterns—and sometimes those patterns lead it astray.
Hallucinations are one of the most significant challenges in AI today, and they're particularly concerning in domains where accuracy matters—like publishing, medicine, law, and finance.
Does an LLM Recall Training Data for Inference?
This is a crucial question for publishers, and the answer is nuanced.
No, an LLM does not retain actual copies of its training data. The model doesn't have a file cabinet with books stored inside it. During training, the content is processed and internalized into the model's parameters—but the original text is not stored.
Think of learning to play piano from sheet music. You study the sheet music—the notes, the rhythms, the dynamics—and practice until the piece is committed to memory. Once you can play it from memory, you no longer need the sheet music.

If someone asked you to write down the sheet music from memory, you could probably get close—but you'd be reconstructing it from your internalized understanding, not photocopying a stored file. Some parts might be perfect. Others might have small errors.
This is exactly what happens when ChatGPT reproduces text like The Art of War. It's not retrieving a stored copy—it's predicting what the text should be based on deeply internalized patterns. And because The Art of War is so well-known and widely reproduced across its training data, the prediction is remarkably accurate.
Think of it another way: the music is "in the brain" of the pianist, not "on the sheet music." The patterns, structures, and relationships have been absorbed—but the original documents are gone.
This distinction matters enormously for publisher concerns about consent, credit, and compensation. The content isn't "stored"—it's "learned from." And that difference has profound legal, ethical, and economic implications.
How Does an LLM Stay Current with New Data?
Training is a discrete event with a definite beginning and end. A model is trained on data up to a certain point in time, and then training stops.
This creates an inherent limitation: the model's knowledge has a cutoff date. For example, GPT-4 was initially trained on data through September 2021. It literally didn't know about anything that happened after that date.
Why not just keep training? Because training is extraordinarily expensive. It costs tens or hundreds of millions of dollars in computing resources, takes weeks or months to complete, and requires massive amounts of energy. You can't simply "update" a model the way you update an app on your phone. Retraining means starting the entire process over—or nearly so.
So how do AI companies keep their models current? Two main approaches have emerged: Fine-Tuning and RAG.
Fine-Tuning
Fine-tuning is a way to update an existing LLM without completely retraining it from scratch.
Think back to our piano analogy. Imagine you've already learned to play a piece, but your teacher wants you to adjust the tempo and add more dynamics. You don't need to re-learn the entire piece—you just need to refine specific aspects of your performance.
That's fine-tuning. It takes an already-trained model and adjusts its behavior or focus in specific areas. For example:
- You could fine-tune a model on legal terminology to make it better at drafting legal documents
- You could fine-tune it on a specific brand's tone of voice to make it sound like that company's communications
- You could fine-tune it on medical literature to improve its accuracy in healthcare contexts
Fine-tuning is faster and cheaper than full retraining, but it's still a significant undertaking that requires expertise, computing resources, and carefully curated data.
RAG (Results-Augmented Generation)
RAG takes a completely different approach. Instead of changing the model itself, RAG feeds new information directly into the model's context window at the time of inference.
The context window is essentially the model's short-term memory. It's the amount of text the model can "see" and work with at any given time. Early versions of ChatGPT had very limited context windows—they'd literally forget what you said at the beginning of a conversation. The latest models can hold context windows equivalent to multiple entire books.
Here's how RAG works in practice: when a user asks a question, the system first searches a knowledge base for relevant information. It then feeds that information into the model's context window along with the user's question. The model generates its response using both its trained knowledge and the new information it was just given.
Think of it like a customer support representative. When a customer calls with a question, the rep doesn't know the answer from memory. Instead, they search their knowledge base, find the relevant article or policy, and then synthesize a helpful response using that information. The rep's value isn't in memorizing everything—it's in their ability to quickly find and communicate the right information.
An LLM with RAG functions similarly. It takes the retrieved information, analyzes it using the patterns it learned during training, and generates a response that synthesizes the new data with its existing understanding.
What Did We Learn About LLMs?
Let's summarize the key concepts:
- Modern AI excels at prediction, not true intelligence. ChatGPT doesn't think—it predicts the most likely next sequence of text based on patterns.
- Training is where an LLM learns the rules. It consumes vast amounts of text and internalizes the patterns, structures, and relationships within it. Training is expensive, time-consuming, and happens as a discrete event.
- Inference is where an LLM applies its training. When you interact with ChatGPT, that's inference—the model using its learned patterns to generate responses.
- Hallucinations occur when the model predicts beyond its knowledge. The model always generates a response, even when it doesn't actually know the answer—leading to confident but incorrect outputs.
- Training data is internalized, not stored. The model learns patterns from content but doesn't retain copies of it—much like a pianist who's memorized a piece no longer needs the sheet music.
- The context window functions as short-term memory. It's the amount of information the model can work with at any given time.
- Fine-tuning refines a model's behavior without complete retraining—like adjusting your piano technique without re-learning the piece.
- RAG provides access to new information at inference time by feeding relevant data into the context window—like a customer support rep searching a knowledge base.
Understanding these concepts is the foundation for productive conversations about AI's role in publishing. The technology isn't magic—it's powerful pattern recognition at an unprecedented scale. And once you understand how it works, the fear gives way to clarity about both the risks and the opportunities.
This article is a companion to a 4-part series on AI and the Future of Book Publishing:
Stay in the loop
Get the latest insights on AI, content licensing, and the future of publishing.
